-
1. 큰 그림 보기(목적 파악: 뭘 위해서 데이터를 찾는 것인지)
2. 데이터 구하기
3. 데이터로부터 인사이트를 얻기 위해 탐색, 시각화
4. 머신러닝 알고리즘을 위해 데이터 준비
5. 모델을 선택하고 훈련시키기
6. 모델을 미세 튜닝
7. 솔루션 제시
8. 시스템을 론칭하고, 모니터링하고, 유지 보수
실제 데이터로 작업
· 유명한 공개 데이터 저장소
- OpenML(https://openml.org)
- 캐글(https://kaggle.com/datasets)
- PapersWithCode(https://paperswithcode.com/datasets)
- UC 어바인 머신러닝 저장소(https://archive.ics.uci.edu/ml)
- 아마존 AWS 데이터셋(https://registry.opendata.aws)
- 텐서플로 데이터셋(https://tensorflow.org/datasets)
· 메타 포털(공개 데이터 저장소가 나열되어 있는 페이지)
- 데이터 포털(https://dataportals.org)
- 오픈 데이터 모니터(https://opendatamonitor.eu)
· 인기 있는 공개 데이터 저장소가 나열되어 있는 다른 페이지
- 위키백과 머신러닝 데이터셋 목록(https://homl.info/9)
- Quora(https://homl.info/10)
- 데이터셋 서브레딧(https://www.reddit.com/r/datasets)
머신러닝 프로젝트 처음부터 끝까지
from pathlib import Path import pandas as pd import tarfile import urllib.request def load_housing_data(): tarball_path = Path('datasets/housing.tgz') if not tarball_path.is_file(): Path('datasets').mkdir(parents=True, exist_ok=True) url = 'https://github.com/ageron/data/raw/main/housing.tgz' urllib.request.urlretrieve(url, tarball_path) with tarfile.open(tarball_path) as housing_tarball: housing_tarball.extractall(path='datasets') return pd.read_csv(Path('datasets/housing/housing.csv')) housing = load_housing_data() housing.head()
housing.info()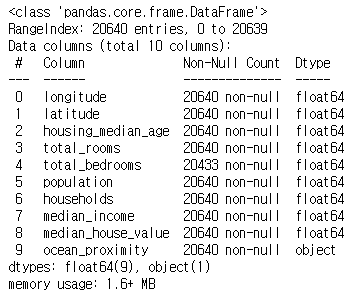
housing['ocean_proximity'].value_counts()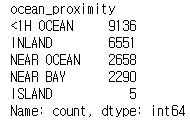
housing.describe()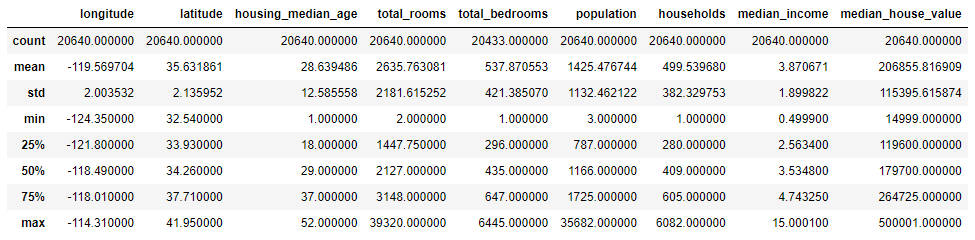
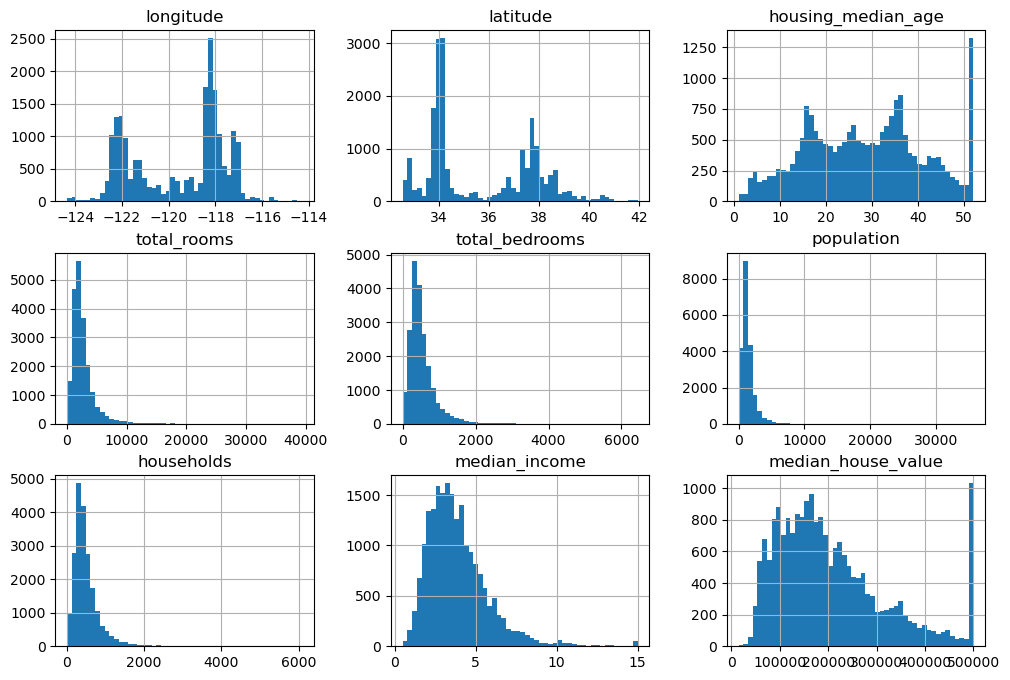
housing.hist(bins=50, figsize=(12, 8))
# 테스트 세트 만들기 import numpy as np def shuffle_and_split_data(data, test_ratio): shuffled_indices = np.random.permutation(len(data)) test_set_size = int(len(data) * test_ratio) test_indices = shuffled_indices[:test_set_size] train_indices = shuffled_indices[test_set_size:] return data.iloc[train_indices], data.iloc[test_indices] train_set, test_set = shuffle_and_split_data(housing, 0.2) print(len(train_set)) print(len(test_set))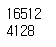
from zlib import crc32 def is_id_in_test_set(identifier, test_ratio): return crc32(np.int64(identifier)) < test_ratio * 2**32 def split_data_with_id_hash(data, test_ratio, id_column): ids = data[id_column] in_test_set = ids.apply(lambda id_: is_id_in_test_set(id_, test_ratio)) return data.loc[~in_test_set], data.loc[in_test_set] housing_with_id = housing.reset_index() # index 열이 추가된 데이터프레임이 반환됨 train_set, test_set = split_data_with_id_hash(housing_with_id, 0.2, 'index') housing_with_id['id'] = housing['longitude'] * 1000 + housing['latitude'] train_set, test_set = split_data_with_id_hash(housing_with_id, 0.2, 'id') from sklearn.model_selection import train_test_split train_set, test_set = train_test_split(housing, test_size=0.2, random_state=42) train_set.head()
import matplotlib.pyplot as plt housing['income_cat'] = pd.cut(housing['median_income'], bins=[0., 1.5, 3.0, 4.5, 6, np.inf], labels=[1, 2, 3, 4, 5]) housing['income_cat'].value_counts().sort_index().plot.bar(rot=0, grid=True) plt.xlabel('Income Category') plt.ylabel('Number of districts')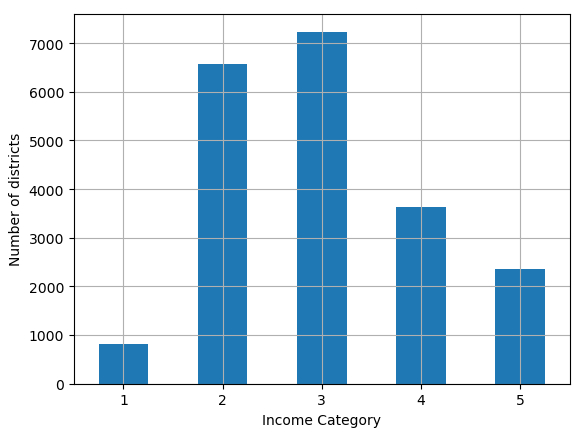
C:\Users\\Desktop\project\jupyter_notebook\ml 디렉터리 2023-12-06 오후 02:27 <DIR> . 2023-12-06 오후 02:24 <DIR> .. 2023-12-06 오후 02:27 <DIR> .ipynb_checkpoints 2023-12-06 오후 02:25 <DIR> datasets 2023-12-06 오후 02:27 176,356 머신러닝 개념.ipynb 1개 파일 176,356 바이트 4개 디렉터리 159,471,996,928 바이트 남음 C:\Users\\Desktop\project\jupyter_notebook\ml>cd datasets C:\Users\\Desktop\project\jupyter_notebook\ml\datasets>dir C 드라이브의 볼륨에는 이름이 없습니다. 볼륨 일련 번호: 52A9-0E40 C:\Users\\Desktop\project\jupyter_notebook\ml\datasets 디렉터리 2023-12-06 오후 02:25 <DIR> . 2023-12-06 오후 02:27 <DIR> .. 2022-02-21 오전 05:34 <DIR> housing 2023-12-06 오후 02:25 449,115 housing.tgz 1개 파일 449,115 바이트 3개 디렉터리 159,464,611,840 바이트 남음 C:\Users\\Desktop\project\jupyter_notebook\ml\datasets>tar -zxvf housing.tgz x housing/ x housing/housing.csv C:\Users\\Desktop\project\jupyter_notebook\ml\datasets>tar tar: Must specify one of -c, -r, -t, -u, -x압축 풀림
'머신러닝' 카테고리의 다른 글
보스턴 주택 가격 회귀 (0) 2024.01.26 사용자 행동 인식 데이터 세트 (0) 2024.01.17 피마 인디언 당뇨병 예측 (0) 2024.01.16 타이타닉 생존자 예측 (0) 2024.01.15 머신러닝 개념 (0) 2023.12.04