-
SQL 기본 문법데이터베이스/SQL 2023. 10. 27. 14:52
DBname : DBMADANG CREATE TABLE Book ( bookid NUMBER(2) PRIMARY KEY, bookname VARCHAR2(40), publisher VARCHAR2(40), price NUMBER(8) ); CREATE TABLE Customer ( custid NUMBER(2) PRIMARY KEY, name VARCHAR2(40), address VARCHAR2(50), phone VARCHAR2(20) ); CREATE TABLE Orders ( orderid NUMBER(2) PRIMARY KEY, custid NUMBER(2) REFERENCES Customer(custid), bookid NUMBER(2) REFERENCES Book(bookid), saleprice NUMBER(8), orderdate DATE ); /* Book, Customer, Orders 데이터 생성 */ INSERT INTO Book VALUES(1, '축구의 역사', '굿스포츠', 7000); INSERT INTO Book VALUES(2, '축구아는 여자', '나무수', 13000); INSERT INTO Book VALUES(3, '축구의 이해', '대한미디어', 22000); INSERT INTO Book VALUES(4, '골프 바이블', '대한미디어', 35000); INSERT INTO Book VALUES(5, '피겨 교본', '굿스포츠', 8000); INSERT INTO Book VALUES(6, '역도 단계별기술', '굿스포츠', 6000); INSERT INTO Book VALUES(7, '야구의 추억', '이상미디어', 20000); INSERT INTO Book VALUES(8, '야구를 부탁해', '이상미디어', 13000); INSERT INTO Book VALUES(9, '올림픽 이야기', '삼성당', 7500); INSERT INTO Book VALUES(10, 'Olympic Champions', 'Pearson', 13000); INSERT INTO Customer VALUES (1, '박지성', '영국 맨체스타', '000-5000-0001'); INSERT INTO Customer VALUES (2, '김연아', '대한민국 서울', '000-6000-0001'); INSERT INTO Customer VALUES (3, '장미란', '대한민국 강원도', '000-7000-0001'); INSERT INTO Customer VALUES (4, '추신수', '미국 클리블랜드', '000-8000-0001'); INSERT INTO Customer VALUES (5, '박세리', '대한민국 대전', NULL); INSERT INTO Orders VALUES (1, 1, 1, 6000, TO_DATE('2020-07-01','yyyy-mm-dd')); INSERT INTO Orders VALUES (2, 1, 3, 21000, TO_DATE('2020-07-03','yyyy-mm-dd')); INSERT INTO Orders VALUES (3, 2, 5, 8000, TO_DATE('2020-07-03','yyyy-mm-dd')); INSERT INTO Orders VALUES (4, 3, 6, 6000, TO_DATE('2020-07-04','yyyy-mm-dd')); INSERT INTO Orders VALUES (5, 4, 7, 20000, TO_DATE('2020-07-05','yyyy-mm-dd')); INSERT INTO Orders VALUES (6, 1, 2, 12000, TO_DATE('2020-07-07','yyyy-mm-dd')); INSERT INTO Orders VALUES (7, 4, 8, 13000, TO_DATE('2020-07-07','yyyy-mm-dd')); INSERT INTO Orders VALUES (8, 3, 10, 12000, TO_DATE('2020-07-08','yyyy-mm-dd')); INSERT INTO Orders VALUES (9, 2, 10, 7000, TO_DATE('2020-07-09','yyyy-mm-dd')); INSERT INTO Orders VALUES (10, 3, 8, 13000, TO_DATE('2020-07-10','yyyy-mm-dd')); CREATE TABLE Imported_Book ( bookid NUMBER, bookname VARCHAR(40), publisher VARCHAR(40), price NUMBER(8) ); INSERT INTO Imported_Book VALUES(21, 'Zen Golf', 'Pearson', 12000); INSERT INTO Imported_Book VALUES(22, 'Soccer Skills', 'Human Kinetics', 15000); COMMIT;테이블 구조 DDL
CREATE(생성) / ALTER(변경) / DROP(삭제)
테이블 데이터 DML
SELECT(검색) / INSERT(삽입) / UPDATE(수정) / DELETE(삭제)
SELECT phone FROM customer WHERE name='김연아';
SELECT bookname, publisher FROM Book WHERE price >= 10000;
SELECT bookname, price FROM Book; SELECT price, bookname FROM Book;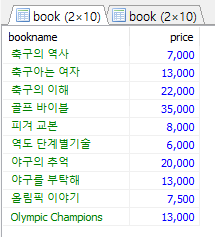

명령어에 적은 순서대로 출력 중복 제거 DISTINCT
SELECT DISTINCT publisher FROM Book;
비교
SELECT * FROM Book WHERE price BETWEEN 10000 AND 20000; SELECT * FROM Book WHERE price >= 10000 AND price <= 20000;
둘 다 똑같은 결과 집합
SELECT * FROM Book WHERE publisher IN ('굿스포츠', '대한미디어'); SELECT * FROM Book WHERE publisher NOT IN ('굿스포츠', '대한미디어');

포함 / 포함 X 패턴
와일드 문자의 종류
와일드 문자 의미 사용 + 문자열 연결 '골프' + '바이블' : '골프 바이블' % 0개 이상의 문자열과 일치 '%축구%': 축구를 포함하는 문자열 [] 한 개의 문자와 일치 '[0-5]%': 0~5 사이의 숫자로 시작하는 문자열 [^] 한 개의 문자와 불일치 '[0-5]%': 0~5 사이의 숫자로 시작하지 않는 문자열 _ 특정 위치의 한 개의 문자와 일치 '_구%': 두 번째 위치에 '구'가 들어가는 문자열 /* 도서 이름의 왼쪽 두 번째 위치에 '구'라는 문자열 갖는 도서 검색 */ SELECT * FROM Book WHERE bookname LIKE '_구%';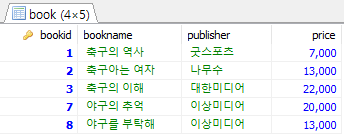
복합 조건
/* 축구에 관한 도서 중 가격이 20,000원 이상인 도서 검색 */ SELECT * FROM Book WHERE bookname LIKE '%축구%' AND price >= 20000; /* 출판사가 '굿스포츠' 혹은 '대한미디어'인 도서 검색 */ SELECT * FROM Book WHERE publisher='굿스포츠' OR publisher='대한미디어';

검색 결과의 정렬
디폴트로 하고 싶으면 ORDER BY 어쩌구 DESC
/* 도서 이름순 검색 */ SELECT * FROM Book ORDER BY bookname; /* 도서의 가격 내림차순 검색, 가격이 같다면 출판사의 오름차순 검색 */ SELECT * FROM Book ORDER BY price DESC, publisher ASC;

집계 함수
집계 함수 종류
집계 함수 문법 사용 예 SUM SUM([ALL | DISTINCT] 속성이름) SUM(price) AVG AVG([ALL | DISTINCT] 속성이름) AVG(price) COUNT COUNT({[[ALL | DISTINCT] 속성이름]|*}) COUNT(*) MAX MAX([ALL | DISTINCT] 속성이름) MAX(price) MIN MIN([ALL | DISTINCT] 속성이름) MIN(price) /* 고객이 주문한 도서의 총 판매 */ SELECT SUM(saleprice) FROM Orders; /* 의미 있는 열 이름을 출력하고 싶으면 속성 이름의 별칭을 지칭하는 AS 키워드 사용 */ SELECT SUM(saleprice) AS 총매출 FROM Orders;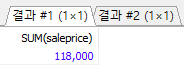
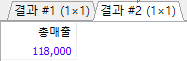
/* 2번 김연아 고객이 주문한 도서의 총 판매액 */ SELECT SUM(saleprice) AS 총매출 FROM Orders WHERE custid=2; /* 고객이 주문한 도서의 총 판매액, 평균값, 최저가, 최고가 구하기 */ SELECT SUM(saleprice) AS Total, AVG(saleprice) AS Average, MIN(saleprice) AS Minimum, MAX(saleprice) AS Maximum FROM Orders;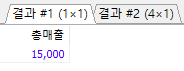

/* 마당서점의 도서 판매 건수 구하기 */ SELECT COUNT(*) FROM Orders;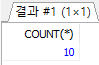
GROUP BY 검색
GROUP BY 쓸 때 SELECT에서 먼저 한번 나와야 함, 순서 상관 X
/* 고객별로 주문한 도서의 총 수량과 총 판매액 */ SELECT custid, COUNT(*) AS 도서수량, SUM(saleprice) AS 총액 FROM Orders GROUP BY custid;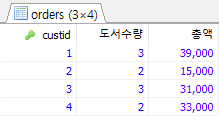
SELECT bookid, COUNT(*) AS 판매수량, SUM(saleprice) AS 판매금액 FROM Orders GROUP BY bookid;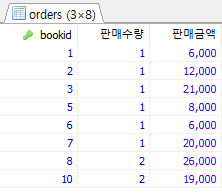
HAVING 절
WHERE 절과 HAVING 절이 같이 포함된 SQL 문은 검색조건이 모호해질 수 있음
HAVING 절은 반드시 GROUP BY 절과 같이 작성, WHERE 절보다 뒤에 나와야 함, 검색 조건에는 SUM, AVG, MAX, MIN, COUNT와 같은 집계 함수가 와야 함
/* 가격이 8,000원 이상인 도서를 구매한 고객에 대해 구객별 주문 도서의 총 수량 */ /* 단, 두 권 이상 구매한 고객만 구하기 */ SELECT custid, COUNT(*) AS 도서수량 FROM Orders WHERE saleprice >=8000 GROUP BY custid HAVING COUNT(*) >=2; SELECT custid, COUNT(*) AS 도서수량 FROM Orders GROUP BY custid HAVING COUNT(*) >=2; SELECT custid, COUNT(*) AS 도서수량 FROM Orders WHERE saleprice >=8000 GROUP BY custid;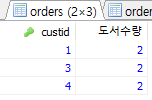
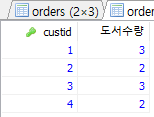
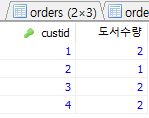
/* Custid별로 총매출, 평균, MIN, MAX, 판매 수량 출력 */ /* Custid 순서로 출력 */ SELECT custid, SUM(saleprice) AS 총매출, AVG(saleprice), MIN(saleprice), MAX(saleprice), COUNT(*) FROM Orders GROUP BY custid;
/* 출판사별로 price의 합과 평균, MIN, MAX 및 책 종류수 출력 */ /* 출판사 이름순 출력, 종류수 1개 이상인 출판사만 출력 */ SELECT publisher, SUM(price) AS 총금액, AVG(price), MIN(price), MAX(price), COUNT(*) AS 종류수 FROM Book GROUP BY publisher HAVING COUNT(*) >=1; SELECT publisher, SUM(price) AS 총금액, AVG(price), MIN(price), MAX(price), COUNT(*) AS 종류수 FROM Book GROUP BY publisher HAVING COUNT(*) >=2;
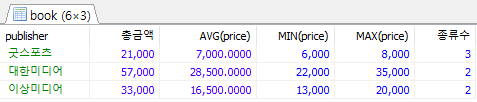
평균 소수점 깔끔하게 정리하는 거 ROUND로 감싸
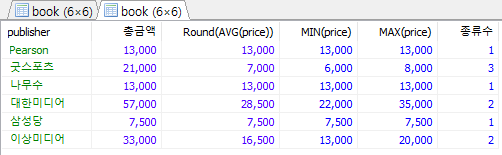
/* 출판사별로 price의 합과 평균, MIN, MAX 및 책 종류수 출력 */ /* 출판사 이름순 출력, 종류수 1개 이상인 출판사만 출력 */ SELECT publisher, SUM(price) AS 총금액, AVG(price), MIN(price), MAX(price), COUNT(*) AS 종류수 FROM Book GROUP BY publisher HAVING COUNT(*) >=1; SELECT publisher, SUM(price) AS 총금액, Round(AVG(price)), MIN(price), MAX(price), COUNT(*) AS 종류수 FROM Book GROUP BY publisher HAVING COUNT(*) >=1;
JOIN
/* 도서를 구매하지 않은 고객 포함해 고객의 이름과 고객이 주문한 도서의 총 구매금액 */ /* 고객 이름순으로 출력 */ SELECT customer.name, sum(orders.saleprice) 주문금액 FROM customer LEFT OUTER JOIN orders ON customer.custid = orders.custid GROUP BY customer.name ORDER BY customer.name;
필터
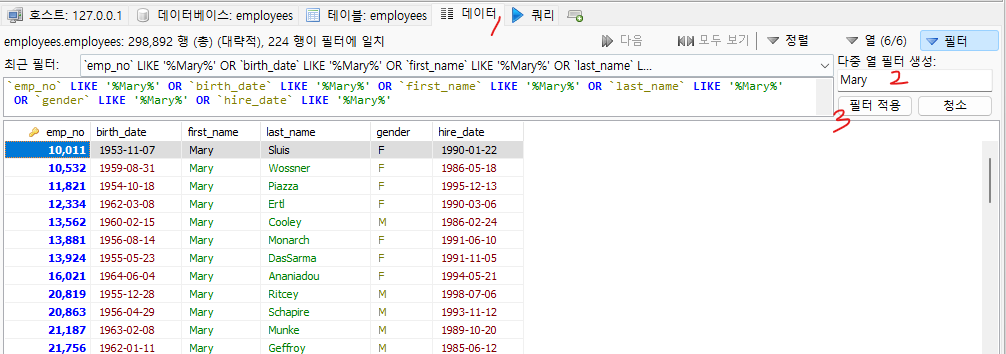
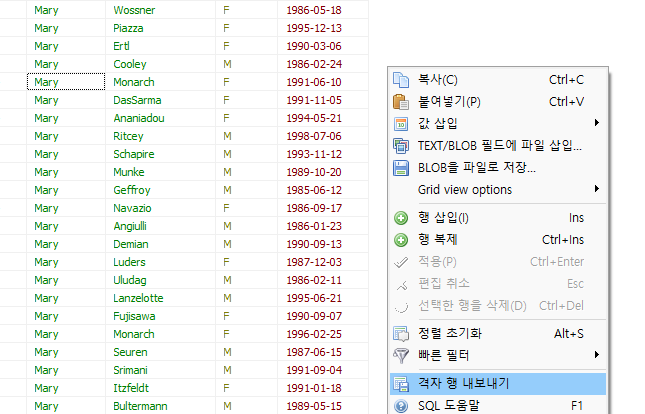
데이터에 한글이 들어갔다면 인코딩을 UTF-8로 변경해야 함
데이터베이스, 테이블 생성
DROP DATABASE IF EXISTS sqlDB; CREATE DATABASE sqlDB; USE sqlDB; CREATE TABLE userTbl (userID CHAR(8) NOT NULL PRIMARY KEY, name VARCHAR(10) NOT NULL, birthYear INT NOT NULL, addr CHAR(2) NOT NULL, mobile1 CHAR(3), mobile2 CHAR(8), height SMALLINT, mDate DATE ); CREATE TABLE buyTbl (num INT AUTO_INCREMENT NOT NULL PRIMARY KEY, userID CHAR(8) NOT NULL, prodName CHAR(6) NOT NULL, groupName CHAR(4), price INT NOT NULL, amount SMALLINT NOT NULL, FOREIGN KEY (userID) REFERENCES userTbl(userID) ); INSERT INTO usertbl VALUES('LSG', N'이승기', 1987, N'서울', '011', '11111111', 182, '2008-8-8'); INSERT INTO usertbl VALUES('KBS', N'김범수', 1979, N'경남', '011', '22222222', 173, '2012-4-4'); INSERT INTO usertbl VALUES('KKH', N'김경호', 1971, N'전남', '019', '33333333', 177, '2007-7-7'); INSERT INTO usertbl VALUES('JYP', N'조용필', 1950, N'경기', '011', '44444444', 166, '2009-4-4'); INSERT INTO usertbl VALUES('SSK', N'성시경', 1979, N'서울', NULL, NULL, 186, '2013-12-12'); INSERT INTO usertbl VALUES('LJB', N'임재범', 1963, N'서울', '016', '66666666', 182, '2009-9-9'); INSERT INTO usertbl VALUES('YJS', N'윤종신', 1969, N'경남', NULL, NULL, 170, '2005-5-5'); INSERT INTO usertbl VALUES('EJW', N'은지원', 1972, N'경북', '011', '88888888', 174, '2014-3-3'); INSERT INTO usertbl VALUES('JKW', N'조관우', 1965, N'경기', '018', '99999999', 172, '2010-10-10'); INSERT INTO usertbl VALUES('BBK', N'바비킴', 1973, N'서울', '010', '00000000', 176, '2013-5-5'); INSERT INTO buytbl VALUES(NULL, 'KBS', N'운동화', NULL, 30, 2); INSERT INTO buytbl VALUES(NULL, 'KBS', N'노트북', N'전자', 1000, 1); INSERT INTO buytbl VALUES(NULL, 'JYP', N'모니터', N'전자', 200, 1); INSERT INTO buytbl VALUES(NULL, 'BBK', N'모니터', N'전자', 200, 5); INSERT INTO buytbl VALUES(NULL, 'KBS', N'청바지', N'의류', 50, 3); INSERT INTO buytbl VALUES(NULL, 'BBK', N'메모리', N'전자', 80, 10); INSERT INTO buytbl VALUES(NULL, 'SSK', N'책', N'서적', 15, 5); INSERT INTO buytbl VALUES(NULL, 'EJW', N'책', N'서적', 15, 2); INSERT INTO buytbl VALUES(NULL, 'EJW', N'청바지', N'의류', 50, 1); INSERT INTO buytbl VALUES(NULL, 'BBK', N'운동화', NULL, 30, 2); INSERT INTO buytbl VALUES(NULL, 'EJW', N'책', N'서적', 15, 1); INSERT INTO buytbl VALUES(NULL, 'BBK', N'운동화', NULL, 30, 2); SELECT * FROM usertbl; SELECT * FROM buytbl;MySQL Client
root 비밀번호 1234 입력
MariaDB [(none)]> source C:\DB백업\sqlDB.sql입력(파일 우클릭 - 경로로 복사)

BETWEEN... AND와 IN() 그리고 LIKE
SELECT userid, name FROM usertbl WHERE birthyear >= 1970 AND height >= 182; SELECT userid, name FROM usertbl WHERE birthyear >= 1970 OR height >= 182;and, or 사용 예시
SELECT userid, height FROM usertbl WHERE height >= 180 AND height <= 183; SELECT Name, height FROM usertbl WHERE height BETWEEN 180 AND 183;
둘 다 같은 결과 SELECT name, addr FROM usertbl WHERE addr='경남' OR addr='전남' OR addr='경북'; SELECT name, addr FROM usertbl WHERE addr IN ('경남', '전남', '경북');
둘 다 같은 결과 SELECT name, height FROM usertbl WHERE name LIKE '김%';김씨인 사람들

SELECT name, height FROM usertbl WHERE name LIKE '_종신';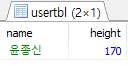
SELECT name, addr FROM usertbl WHERE addr LIKE '경%';
ANY/ALL/SOME 그리고 서브쿼리(SubQuery, 하위쿼리)
SELECT Name, height FROM usertbl WHERE height > 177; SELECT Name, height FROM usertbl WHERE height > (SELECT height FROM usertbl WHERE Name = '김경호');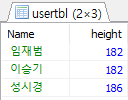
둘 다 같은 결과 SELECT Name, mDate FROM usertbl WHERE mDate >= (SELECT mDate FROM usertbl WHERE Name = '임재범');
SELECT Name, mDate FROM usertbl WHERE mDate >= (SELECT mDate FROM usertbl WHERE Name = '임재범') ORDER BY mDate ASC;
날짜 오름차순 정렬 SELECT name, height FROM userTbl WHERE height >= ANY (SELECT height FROM usertbl WHERE addr = '경남');
중복된 것은 하나만 남기는 DISTINCT
SELECT addr FROM usertbl ORDER BY addr;
우선 보기 편하게 나열
SELECT DISTINCT addr FROM usertbl;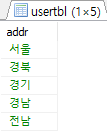
출력 개수 제한하는 LIMIT
USE employees; SELECT emp_no, hire_date FROM employees ORDER BY hire_date ASC;
제일 앞 5건만 사용하면 되는데 30만 건이 더 출력됨
USE employees; SELECT emp_no, hire_date FROM employees ORDER BY hire_date ASC LIMIT 5;LIMIT N 구문 사용

LIMIT절은 'LIMIT 시작, 개수' 또는 'LIMIT 개수 OFFSET 시작' 형식으로도 사용 가능, 시작은 0부터
USE employees; SELECT emp_no, hire_date FROM employees ORDER BY hire_date ASC LIMIT 0, 5; -- 'LIMIT 5 OFFSET 0'과 같음따라서 이렇게도 사용 가능
지역별 거주자 수 출력
USE sqldb; SELECT DISTINCT addr AS 지역, COUNT(*) AS 거주자수 FROM usertbl GROUP BY addr;
최장신 최단신 출력
SELECT Name, height AS 내키, (SELECT MAX(height)FROM usertbl) AS 최장신, (SELECT MIN(height)FROM usertbl) AS 최단신 FROM usertbl WHERE height = (SELECT MAX(height)FROM usertbl) OR height = (SELECT MIN(height)FROM usertbl);
Having 절
SELECT userid AS '사용자', SUM(price*amount) AS '총구매액' FROM buytbl GROUP BY userid;사용자별 총 구매액

SELECT userid AS '사용자', SUM(price*amount) AS '총구매액' FROM buytbl GROUP BY userid HAVING SUM(price*amount) > 1000;총 구매액이 1000 이상인 사용자 출력(WHERE 구문이 아닌 HAVING 절 사용)

ROLLUP
총합 또는 중간 합계가 필요할 때 GROUP BY절과 함께 WITH ROLLUP문을 사용
SELECT num, groupname, SUM(price*amount) AS 비용 FROM buytbl GROUP BY groupname, num WITH ROLLUP;분류별 합계 및 총합
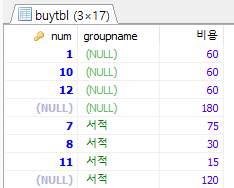

중간 num열이 NULL로 표시되어 있는 추가된 행이 각 그룹의 소합계, 마지막 행은 총합계의 결과
위 구문에서 num은 Primary Key, 각 항목이 보이는 효과
소합계 및 총합계만 필요하다면 num 빼도 됨
SELECT num, groupname, SUM(price*amount) AS 비용 FROM buytbl GROUP BY groupname WITH ROLLUP;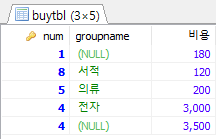
예제 ) 소합계가 180 이상인 소그룹 명과 비용 출력 작은 비용
SELECT groupname, SUM(price*amount) AS 비용 FROM buytbl GROUP BY groupname HAVING SUM(price*amount) >= 180 ORDER BY SUM(price*amount) ASC;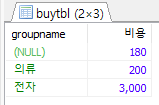
자동으로 증가하는 AUTO_INCREMENT
테이블 속성이 AUTO_INCREMENT로 지정되어 있다면 INSERT에서는 해당 열이 없다고 생각하고 입력
자동으로 1부터 증가하는 값을 입력해 줌
AUTO_INCREMENT로 지정할 때는 꼭 PRIMARY KEY 또는 UNIQUE로 지정해 줘야 하고, 테이블 형은 숫자 형식만 사용 가능
AUTO_INCREMENT로 지정된 열은 INSERT문에서 NULL값을 지정하면 자동으로 값이 입력됨
USE sqlDB; CREATE TABLE testTBL2 (id int AUTO_INCREMENT PRIMARY KEY, userName char(3), age int); INSERT INTO testTBL2 VALUES (NULL, '지민', 25); INSERT INTO testTBL2 VALUES (NULL, '유나', 22); INSERT INTO testTBL2 VALUES (NULL, '유경', 21); SELECT * FROM testTBL2;
SELECT LAST_INSERT_ID()문을 사용하면 마지막에 입력된 값을 보여 줌, 위 경우 3
AUTO_INCREMENT 입력값을 100부터 입력되도록 변경하고 싶은 경우
ALTER TABLE testTBL2 AUTO_INCREMENT=100; INSERT INTO testTBL2 VALUES (NULL, '찬미', 23); SELECT * FROM testTBL2;
증가값을 지정하려면 서버 변수인 @@auto_increment_increment 변수를 변경시켜야 함
예제 ) 초기값 1000, 증가값은 3으로 변경
USE sqlDB; CREATE TABLE testTBL3 (id int AUTO_INCREMENT PRIMARY KEY, userName char(3), age int); ALTER TABLE testTBL3 AUTO_INCREMENT=1000; SET @@auto_increment_increment=3; INSERT INTO testTBL3 VALUES (NULL, '나연', 20); INSERT INTO testTBL3 VALUES (NULL, '정연', 18); INSERT INTO testTBL3 VALUES (NULL, '모모', 19); SELECT * FROM testTBL3;
대량의 데이터 생성
다른 테이블의 데이터를 가져와 대량으로 입력하는 효과
USE sqlDB; CREATE TABLE testTBL4 (id int, Fname varchar(50), Lname varchar(50)); INSERT INTO testTBL4 SELECT emp_no, first_name, last_name FROM employees.employees ;
300,024 생성 확인
테이블 정의까지 생략하고 싶었던 CREATE TABLE... SELECT 구문을 사용할 수도 있음
USE sqlDB; CREATE TABLE testTBL (SELECT emp_no, first_name, last_name FROM employees.employees) ;
생성 확인, 하지만 PRIMARY KEY 등 상세 내용은 입력되지 않으므로 이후 값을 따로 줘야 함
데이터 수정: UPDATE
UPDATE testTBL4 SET Lname = '없음' WHERE Fname = 'Kyoichi''Kyoichi'의 Lname을 '없음'으로 변경
실수로 WHERE절 빼먹으면 전체 행의 Lname이 '없음'으로 변경되므로 주의할 것
전체 테이블 변경할 때는 WHERE절 생략 가능
USE sqlDB; UPDATE buyTBL2 SET price = price * 1.5;와 같은 형식
데이터 수정: DELETE FROM
USE sqlDB; DELETE FROM testTBL4 WHERE Fname = 'Aamer';
'Aamer' 사용자명을 사용 중인 228건의 행 삭제
DELETE FROM testTBL4 WHERE Fname = 'Mary' LIMIT 5;전체가 아닌 조건에 맞는 결과 중 상위 몇 건만 삭제하려면 LIMIT 구문과 함께 사용
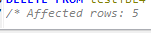
224건의 'Mary' 중 상위 5건만 삭제
대용량 삭제 방법 비교
USE sqlDB; CREATE TABLE bigTBL1 (SELECT * FROM employees.employees); DELETE FROM bigTBL1; USE sqlDB; CREATE TABLE bigTBL2 (SELECT * FROM employees.employees); DROP TABLE bigTBL2; USE sqlDB; CREATE TABLE bigTBL3 (SELECT * FROM employees.employees); TRUNCATE TABLE bigTBL3;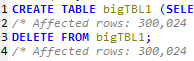
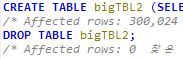
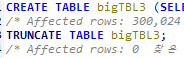
결과 메시지 비교하면 DELETE만 Affected rows가 300,024로 나오고 나머지는 0
DML문인 DELETE는 트래직션 로그를 기록하는 작업 때문에 Affected rows 표시
DDL문인 DROP문은 테이블 자체 삭제, DDL문은 트랜직션을 발생시키지 X
DDL문인 TRUNCATE문의 결과는 DELETE와 동일하지만 TRUNCATE도 DDL문이므로 트래직션 로그를 기록하지 X

조건부 데이터 입력, 변경
먼저 멤버 테이블 정의, 데이터 입력
USE sqlDB; CREATE TABLE memberTBL (SELECT userID, name, addr FROM userTbl LIMIT 3); ALTER TABLE memberTBL ADD CONSTRAINT pk_memberTBL PRIMARY KEY (userID); SELECT * FROM memberTBL;
INSERT INTO memberTBL VALUES('BBK', '비비코', '미국'); INSERT INTO memberTBL VALUES('SJH', '서장훈', '서울'); INSERT INTO memberTBL VALUES('HJY', '현주엽', '경기'); SELECT * FROM memberTBL;
PK 중복으로 오류 발생 
멤버 테이블을 확인해 보면 오류로 인해 나머지 2건도 입력되지 않음
INSERT IGNORE INTO memberTBL VALUES('BBK', '비비코', '미국'); INSERT IGNORE INTO memberTBL VALUES('SJH', '서장훈', '서울'); INSERT IGNORE INTO memberTBL VALUES('HJY', '현주엽', '경기'); SELECT * FROM memberTBL;(경고창 무시)

첫 번째 데이터는 오류로 들어가지 않았지만 2건은 추가로 입력된 것 확인
INSERT IGNORE는 PK 중복이더라도 오류 발생시키지 않고 무시하고 넘어감
기본 키가 중복되면 데이터가 수정되도록
INSERT INTO memberTBL VALUES('BBK', '비비코', '미국') ON DUPLICATE KEY UPDATE name='비비코', addr='미국'; INSERT INTO memberTBL VALUES('DJM', '동짜몽', '일본') ON DUPLICATE KEY UPDATE name='동짜몽', addr='일본'; SELECT * FROM memberTBL;
1건 수정, 1건 추가
비재귀적 CTE
재귀적이지 않은 CTE, 단순한 형태이고 복잡한 쿼리 문장을 단순화시키는 데 적합하게 사용될 수 있음
VIEW는 흔적이 남아 계속 불러올 수 있는데, CTE는 같이 소멸되므로 다시 사용 X
USE sqlDB; SELECT userid AS '사용자', SUM(price*amount) AS '총구매액' FROM buytbl GROUP BY userid;
앞에서 했던 총 구매액 구하는 것
구매액이 많은 사용자 순서로 정렬?
WITH abc(userid, total) AS (SELECT userid, SUM(price*amount) FROM buyTBL GROUP BY userid) SELECT * FROM abc ORDER BY total DESC;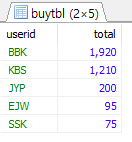
지역별로 가장 큰 키 1명씩 뽑은 후, 사람들의 키의 평균 내기
1. 각 지역별로 가장 큰 키를 뽑는 쿼리 만들기
SELECT addr, MAX(height) FROM userTBL GROUP BY addr2. 위 쿼리를 WITH 구문으로 묶음
WITH cte_userTBL(addr, maxHeight) AS ( SELECT addr, MAX(height) FROM userTBL GROUP BY addr)3. 키의 평균을 구하는 쿼리 작성
SELECT AVG(키) FROM CTE_테이블이름4. 2, 3단계 쿼리를 합침(키의 평균을 실수로 만들기 위해 키에 1.0을 곱해 실수로 변환)
WITH cte_userTBL(addr, maxHeight) AS ( SELECT addr, MAX(height) FROM userTBL GROUP BY addr) SELECT AVG(maxHeight*1.0) AS '각 지역별 최고키의 평균' FROM cte_userTBL;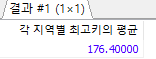
다음 형식과 같은 중복 CTE 허용됨
WITH AAA (컬럼들) AS (AAA의 쿼리문), BBB (컬럼들) AS (BBB의 쿼리문), CCC (컬럼들) AS (CCC의 쿼리문) SELECT * FROM [AAA 또는 BBB 또는 CCC]CCC의 쿼리문에서는 AAA나 BBB를 참조할 수 있지만 AAA의 쿼리문이나 BBB의 쿼리문에서는 CCC를 참조할 수 x
> 아직 정의되지 않은 CTE를 미리 참조할 수 x
'데이터베이스 > SQL' 카테고리의 다른 글
XAMPP 설치 (0) 2023.12.14 SQL 고급 (0) 2023.11.09 MariaDB 유틸리티 사용법 (0) 2023.10.26 데이터베이스 모델링 (0) 2023.10.26 MariaDB 전체 운영 실습 (0) 2023.10.13